简单来说Hive就是可以让你通过撰写SQL就能完成对HDFS的操作,它的底层会将SQL转换为MapRedurce或其他形式。当然,从Hive2开始,官方就不建议默认使用MapReduce引擎,而是建议使用Tez引擎或者是Spark引擎,不过目前一直到最新的3.x版本中mapreduce还是默认的执行引擎。
- 第一代大数据计算引擎:MapReduce
- 第二代大数据计算引擎:Tez,它的存在感比较低,源于MapReduce,主要和Hive结合在一起使用,核心思想是将Map和Reduce两个操作进一步拆分,使其更加灵活。
- 第三代大数据计算引擎:Spark,Speak在当时属于一个划时代的产品,改变了之前基于磁盘的计算思路,而是采用内存计算。数据读取后中间的计算全部在内存进行,只有最终的结果会写入磁盘,而MapReduce的中间结果是会写磁盘的, 所以效率没有Spark高。
- 第四代大数据计算引擎:Flink,Flink是一个可以支持纯实时数据计算的计算引擎,在实时计算领域要优于Saprk。
# Hive下载
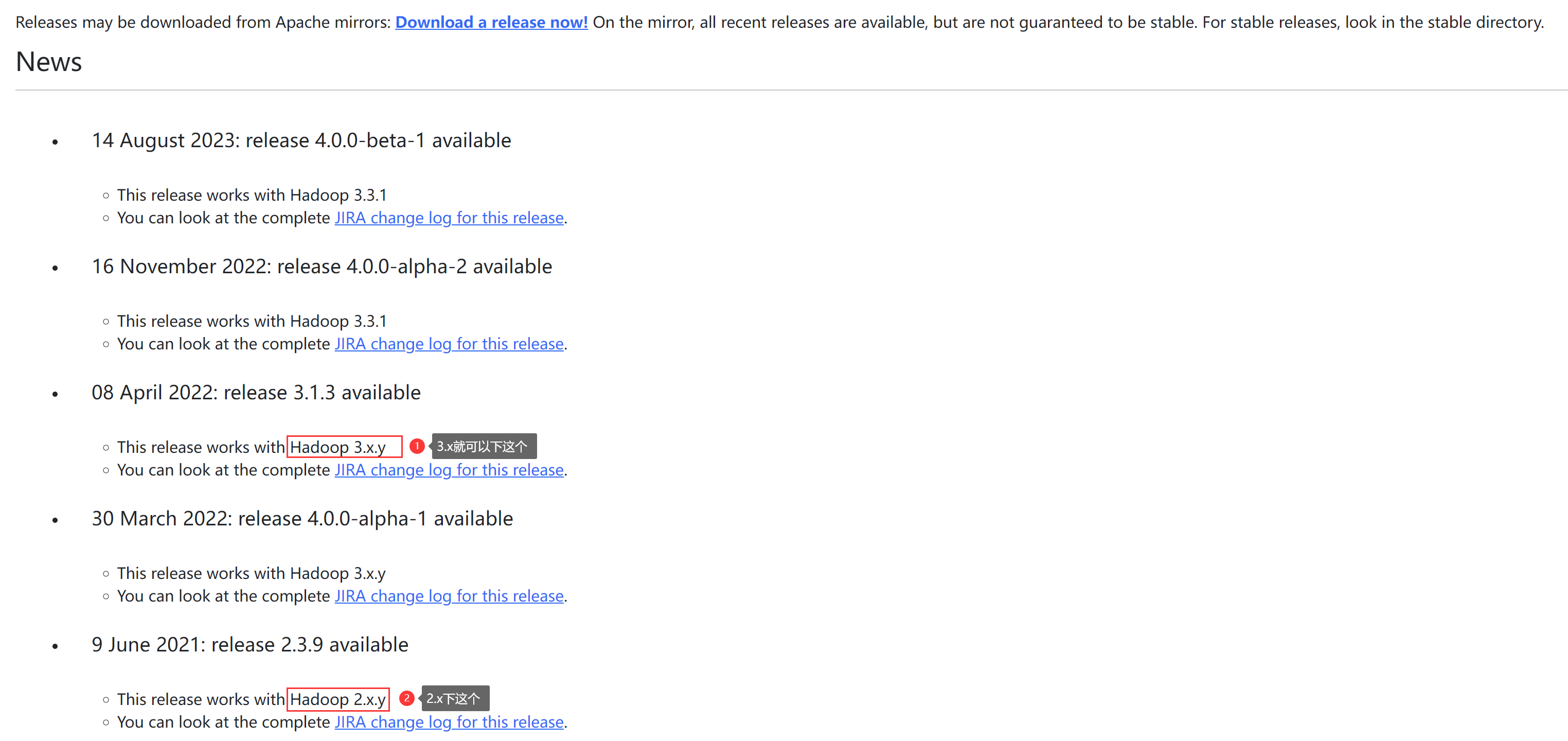
Hive与Hadoop之间是有版本对应关系的,版本查看点击跳转 (opens new window),下载地址 (opens new window),例如我下载的就是:apache-hive-3.1.3-bin.tar.gz
# Hive安装
将Hive安装到centos7服务器上,服务器要求安装Hadoop和JDK,将安装包上传至/usr/local/soft/hive,然后执行命令
[root@flume hive]# tar -zxvf apache-hive-3.1.3-bin.tar.gz
[root@flume hive]# cd apache-hive-3.1.3-bin/conf/
[root@flume conf]# mv hive-env.sh.template hive-env.sh
[root@flume conf]# mv hive-default.xml.template hive-site.xml
在 hive-env.sh 文件的末尾直接增加下面三行内容【根据实际的路径配置】
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
export HIVE_HOME=/usr/local/soft/hive/apache-hive-3.1.3-bin
export HADOOP_HOME=/usr/local/soft/hadoop/hadoop-3.2.4
修改hive-site.xml,注意数据库IP、账号和密码等配置,修改配置文件的内容,而不是直接在尾部添加
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.95.112:3306/hive?serverTimezone=Asia/Shanghai</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>数据库账号</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>数据库密码</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/data/hive_repo/querylog</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/data/hive_repo/scratchdir</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/data/hive_repo/resources</value>
</property>
# 上传MySQL的jar包
下载地址:点击跳转 (opens new window),将jar包上传至/usr/local/soft/hive/apache-hive-3.1.3-bin/lib/
# 修改Hadoop配置
修改各个机器Hadoop的core-site.xml配置,在这个配置文件增加如下内容:
<configuration>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
同步Hadoop配置文件到其他机器,并重启Hadoop集群
[root@bigdata03 ~]# cd /usr/local/soft/hadoop/hadoop-3.2.4/etc/hadoop/
[root@bigdata03 hadoop]# vi core-site.xml
[root@bigdata03 hadoop]# scp -rq core-site.xml bigdata04:/usr/local/soft/hadoop/hadoop-3.2.4/etc/hadoop/
[root@bigdata03 hadoop]# scp -rq core-site.xml bigdata05:/usr/local/soft/hadoop/hadoop-3.2.4/etc/hadoop/
[root@bigdata03 etc]# cd ../sbin/
[root@bigdata03 sbin]# stop-all.sh
[root@bigdata03 sbin]# start-all.sh
# 初始化Hive的Metastore
显示后面这些行的内容就代表成功,如果失败查看下文,会有失败原因及解决方案。
[root@flume apache-hive-3.1.3-bin]# bin/schematool -dbType mysql -initSchema
Metastore connection URL: jdbc:mysql://192.168.95.112:3306/hive?serverTimezone=Asia/Shanghai
Metastore Connection Driver : com.mysql.cj.jdbc.Driver
Metastore connection User: root
Starting metastore schema initialization to 3.1.0
Initialization script hive-schema-3.1.0.mysql.sql
Initialization script completed
schemaTool completed