
软件架构风格-数据流风格 理论
数据流风格中,所有的数据按照流的形式在执行过程中前进,不存在结构的反复和重构,就像工厂中的汽车流水线一样,数据在流水线的各个节点上被加工。每完成一个环节,数据流都会被送入下一个环节,最终输出处理后的完整结果。 在整个流动过程中,数据经过有序的数据处理组件进行处理,整个数据流动保持指定方向,最后完成整体输出。数据流风格架构又可以细分两种具体的架构风格:批处理序列和管道过滤器。
# 批处理风格
批处理风格通常会由总体协调安排批处理过程,保证其每一步处理都是独立的,并且顺序执行。具体来看有以下特点:
- 强时间顺序:只有当前一步的计算任务处理完成后,后一步处理才能开始。计算务前后顺序明确。
- 强完整性:数据传送在计算单元之间通过指定的数据交互方式传递。每一步要确保数据完整,才可以向下一步发起数据传送。
- 强控制力度:有独立的顺序控制和时间把控机制,并辅以数据检查等功能。
举几个例子说明一下:
传统定制批处理任务:比如银行的夜间批量结算和大小额清算,券商的夜间交易结算和证券系统对账等。特点是通常运行在指定时间,数据流庞大,每一步有精确的数据处理要求和校验机制,顺序逻辑清晰。
Hadoop大数据处理:Hadoop在处理过程中有明确的步骤安排,比如map几次,shuffle几次,再reduce完成数据处理。
Apache Beam大数据处理:当前比较火的批量处理工具是Apache Beam。虽然它同时支持批处理和流处理,但是在日常使用中其批处理的优势更加明显。它定义类专门的数据集、计算过程、管道和执行器。能够形成有向无环图,来保证数据流的方向和结果输出。
# 管道过滤器风格
管道过滤器风格,由管道和过滤器两部分组成。如下图所示:
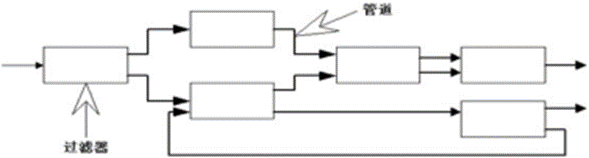
- 过滤器:是其中的核心构件,负责业务的处理。它从用户或者上游管道获得输入数据,进行数据的变换及增量计算,处理完成后,通过下游管道传递给另一个过滤器。过滤器是独立的实体,它不能与其他的过滤器共享数据,而且一个过滤器不知道它上游和下游的其他过滤器信息。
- 管道:是一种数据传输途径。可以是Unix/Linux操作系统的管道文件,也可以是消息队列,只要能确保数据的先进先出,单向进出就可以了。
管道-过滤器的经典案例也很多,比如:
编译器:在编译器系统中,一个阶段(包括词法分析、语法分析、语义分析和代码生成) 的输出是另一个阶段的输入,处理阶段是是以数据流进行编译过程驱动流转的。
操作系统管道过程:比如经典的Linux命令"ps -ef|grep java",就是在系统中检查java进程信息,其中的”ps -ef“和”grep java“就是两个过滤器,各自处理相关流程步骤,中间的"|"标识,就是管道,负责在两个过滤器之间进行有向传输。
# 数据流风格总结
数据流的两种子风格的相似点如下:
- 解耦:类似福特流水线的优势,它将每个阶段的处理过程进行了隔离,使得软件构件具有良好的隐蔽性和高内聚、低耦合的特点; 每个批处理过程或者过滤器独立管理,可以方便地进行替换。
- 复用:支持软件重用,只要提供适合数据处理的需求,任何两个批处理过程和过滤器都可有序被连接起来。
- 高吞吐:数据流风格在5大风格中是最适合大数据的架构风格。它可以完成各种大量数据互通、传递、处理的过程。同时,批处理序列风格与管道过滤器风格的不同点也很多:
- 计划性:批处理通常由时间规划和任务调度统筹安排;而管道过滤器是递增式处理过程,是由数据驱动的处理流程。
- 敏捷性:批处理需要完成前序任务,再进行后续任务,通常整个任务处理周期较长,通常以分钟、小时、天为单位;管道过滤器在传输过程中没有整体处理的概念,可以快速将一份小的数据变动流过相关的过滤器和管道,实现秒级、分钟级的快速响应。