
Hadoop环境搭建与JDK的安装
cv大魔王 2023-10-08 大数据Hadoop 分享
# 安装jdk
yum install java-1.8.0-openjdk
yum install -y java-devel
java #检查是否安装成功
需要记录jdk真实的安装地址,输入命令查询到后手动复制下,后面要用
cd /usr/lib/jvm 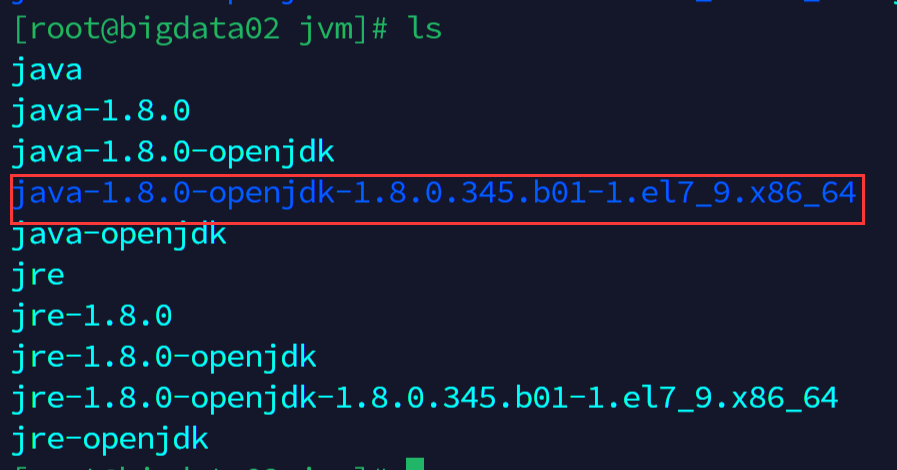
# 安装Hadoop并设置环境变量
将hadoop安装包复制到Linux中/usr/local/soft/hadoop目录下,解压并设置环境变量
cd /usr/local/soft/hadoop
tar -zxvf hadoop-3.2.4.tar.gz #解压
vi /etc/profile
source /etc/profile #添加完环境变量后执行
设置环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64 #这里注意版本号的不同
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/soft/hadoop/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
输入hadoop查看控制台是否有输出。
# 修改Hadoop相关配置文件
cd /usr/local/soft/hadoop/hadoop-3.2.4/etc/hadoop/
vi hadoop-env.sh
1.hadoop-env.sh文件中底部输入
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.382.b05-1.el7_9.x86_64
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
2.修改core-site.xml文件,bigdata03是配置的hostname,配置方法见[Linux常用配置锦集](/Linux/Centos7/Linux常用配置锦集.html)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata03:9000</value>
</property>
<property>
<name>hadoop.tem.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
3.修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata03:50090</value>
</property>
</configuration>
4.修改mapred-site.xml文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.修改yarn-site.xml文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.ev-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata03</value>
</property>
</configuration>
6.修改workers文件,设置集群中从节点的主机名信息
bigdata04
bigdata05
# 修改启动文件
首先需要修改文件start-dfs.sh和stop-dfs.sh
[root@bigdata01 sbin]# cd /usr/local/soft/hadoop/hadoop-3.2.3/sbin
[root@bigdata01 sbin]# vi start-dfs.sh
# ============ 下面是文件内容,写在文件的前面注释中间部分 ============
# ……
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# Start hadoop dfs daemons.
# Optinally upgrade or rollback dfs state.
# Run this on master node.、
# ……
[root@bigdata01 sbin]# vi stop-dfs.sh
# ============ 也是写前面 ============
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改sbin目录下的 start-yarn.sh、stop-yarn.sh 两个脚本文件,在文件前面增加如下内容
[root@bigdata01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@bigdata01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
# 复制修改好的hadoop文件夹到集群
scp -rq hadoop-3.2.4 bigdata04:/usr/local/soft/hadoop/
scp -rq hadoop-3.2.4 bigdata05:/usr/local/soft/hadoop/
# 格式化文件系统
配置文件到这就修改好了,但是还不能直接启动,因为Hadoop中的HDFS是一个分布式的文件系统,文件系统在使用之前是需要先格式化的,就类似我们买一块新的磁盘,在安装系统之前需要先格式化才可以使用
cd /usr/local/soft/hadoop/hadoop-3.2.4
bin/hdfs namenode -format #格式化操作,这个命令如果执行成功了就不要再执行一遍了,如果需要重新执行,删除/data/hadoop_repo目录下的内容
注意:格式化操作只能执行一次,如果格式化的时候失败了,可以修改配置文件后再执行格式化,如果格式化成功了就不能再重复执行了,否则集群就会出现问题。 如果确实需要重复执行,那么需要把**/data/hadoop_repo**目录中的内容全部删除,再执行格式化
可以这样理解,我们买一块新磁盘回来装操作系统,第一次使用之前会格式化一下,后面你会没事就去格式化一下吗?
# 启动分布式集群
- 启动命令:start-all.sh (在sbin目录下)
- 退出命令:stop-all.sh
# 集群节点之间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集 群的稳定性,甚至导致集群出问题。
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步,但是执行的时候提示找不到ntpdata命令,默认是没有ntpdate命令的,需要使用yum在线安装,执行命令yum install -y ntpdate,三台机器都执行以下命令。
[root@bigdata01 hadoop-3.2.3]# yum install -y ntpdate #安装命令
[root@bigdata01 hadoop-3.2.3]# ntpdate -u ntp.sjtu.edu.cn #时间同步命令
10 Oct 20:03:04 ntpdate[8613]: adjust time server 111.230.189.174 offset -0.000877 sec
[root@bigdata01 hadoop-3.2.3]# vi /etc/crontab #定时任务
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn #定时任务内容
评论区
暂无评论~~